
해시
이번 포스팅은 자료구조의 해시를 정리해보겠습니다.
해시
해시란?
해시란 데이터를 다루는 기법 중에 하나며, 검색과 저장이 아주 빠르게 진행됩니다. 빠르게 진행이 되는 이유는 데이터를 검색할 때 사용할 key와 실제 데이터 값이 한 쌍으로 존재하고, key 값이 배열의 인덱스로 변환되기 때문입니다.
해시의 구조
해시는 키와, 해시함수, 해시테이블로 이루어져 있습니다. 해시함수에 의하여 각각의 키값들이 숫자로 변환 됩니다. 그리고 변환된 숫자값 들을 해시테이블의 인자값으로 사용하여 값을 저장하는 구조 입니다.
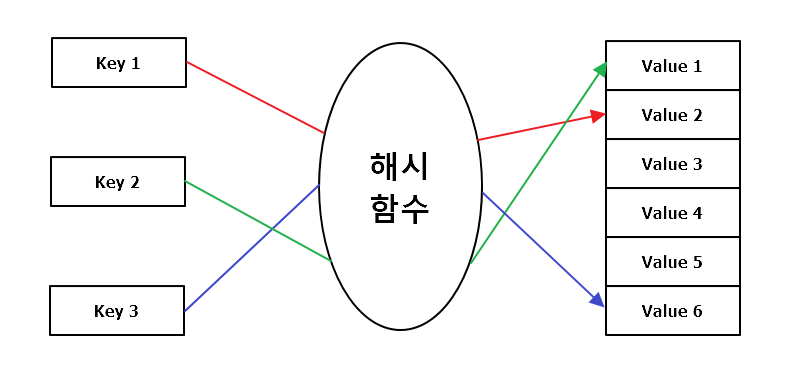
해시함수란?
임의의 길이를 갖는 메시지를 입력받아 고정된 길이의 해시값을 출력하는 함수입니다.
hash('a')
454529464589154098
hash(15)
15
hash(12.34)
783986623132655628
해시 구현 방법
파이썬에서는 해시를 구현 할 수 있도록 딕셔너리 클래스가 존재 함으로 딕셔너리를 활용하겠습니다.
딕셔너리 삽입
파이썬의 딕셔너리 삽입을 보겠습니다. 딕셔너리는 아래와 같이 다양한 형태로 삽입이 가능합니다.
hashd = dict() # hash = {}
hashd[1] = 'apple'
hashd['bannana'] = 3
hashd[(4,5)] = [1,2,3]
hashd[10] = dict({1:'a',2:'b'})
print(hashd)
{1: ‘apple’, ‘bannana’: 3, (4, 5): [1, 2, 3], 10: {1: ‘a’, 2: ‘b’}}
하지만 아래와 같이 키값으로 리스트 또는 딕셔너리 타입같이 배열의 집합 형태는 삽입이 불가 합니다.
hashd[[1,2,3]] = 5
---------------------------------------------------------------------------
TypeError Traceback (most recent call last)
<ipython-input-11-3af137625a5e> in <module>
----> 1 hashd[[1,2,3]] = 5
TypeError: unhashable type: 'list'
hashd[{1,2,3}] = 'orange'
---------------------------------------------------------------------------
TypeError Traceback (most recent call last)
<ipython-input-12-adac31bb085b> in <module>
----> 1 hashd[{1,2,3}] = 'orange'
TypeError: unhashable type: 'set'
이유는 집합과 배열은 해시 함수에 의해서 인덱스로 반환 될 수 없기 때문 입니다.
hash({3,5})
---------------------------------------------------------------------------
TypeError Traceback (most recent call last)
<ipython-input-15-709d1be36a64> in <module>
----> 1 hash({3,5})
TypeError: unhashable type: 'set'
hash([3,5])
---------------------------------------------------------------------------
TypeError Traceback (most recent call last)
<ipython-input-16-f95f6e42fefe> in <module>
----> 1 hash([3,5])
TypeError: unhashable type: 'list'
딕셔너리 수정
파이썬의 딕셔너리 수정을 해보겠습니다.
print(hashd)
{1: ‘apple’, ‘bannana’: 3, (4, 5): [1, 2, 3], 10: {1: ‘a’, 2: ‘b’}}
hashd[1] = 'melon'
print(hashd)
{1: ‘melon’, ‘bannana’: 3, (4, 5): [1, 2, 3], 10: {1: ‘a’, 2: ‘b’}}
hashd['bannana'] = 10
print(hashd)
{1: ‘melon’, ‘bannana’: 10, (4, 5): [1, 2, 3], 10: {1: ‘a’, 2: ‘b’}}
딕셔너리 값 추출
파이썬의 딕셔너리 추출을 해보겠습니다. stack과 queue에도 나오는 .pop을 활용하면 딕셔너리에서 데이터를 뺄 수 있습니다.
print(hashd)
{1: ‘melon’, ‘bannana’: 10, (4, 5): [1, 2, 3], 10: {1: ‘a’, 2: ‘b’}}
print(hashd.pop(1))
print(hashd)
melon
{‘bannana’: 10, (4, 5): [1, 2, 3], 10: {1: ‘a’, 2: ‘b’}}
print(hashd.pop('bannana'))
print(hashd)
10
{(4, 5): [1, 2, 3], 10: {1: ‘a’, 2: ‘b’}}
print(hashd.pop((4, 5)))
print(hashd)
[1, 2, 3]
{10: {1: ‘a’, 2: ‘b’}}
딕셔너리 삭제
파이썬의 딕셔너리 삭제를 해보겠습니다. del을 이용하면 값을 반환하지 않아서 속도가 조금 빠르게 삭제가 가능하지만 큰 차이는 아니라고 합니다.
del hashd[10]
print(hashd)
{}
딕셔너리 루프
딕셔너리를 이용한 알고리즘은 딕셔너리 루프와 딕셔너리 정렬을 가장 많이 사용하고 있습니다. 딕셔너리 루프를 사용할때 키값을 사용할 것인지 Value 값을 이용할 것인지 아니면 둘다 이용 할 것인지 나눌수 있습니다. 그래서 딕셔너리는 각각에 대하여 .keys() .values() .items() 3개의 함수를 가지고 있습니다.
- .keys()는 키값을 리스트 형태로 반환합니다.
- .values() 마찬가지로 value값을 리스트 형태로 반환합니다.
- .items()는 key와 value의 값을 튜플의 리스트 형태로 반환합니다.
실제 함수를 활용해 보겠습니다. 먼저 아래와 같이 연속된 숫자의 key 값에 value 값이 제곱이 되도록 넣어 각각의 함수를 확인해 보겠습니다.
hashd = dict()
for i in range(1,6):
hashd[i] = i ** 2
print(hashd)
{1: 1, 2: 4, 3: 9, 4: 16, 5: 25}
for k in hashd.keys():
print(k)
1
2
3
4
5
for v in hashd.values():
print(v)
1
4
9
16
25
for i in hashd.items():
print(i)
(1, 1)
(2, 4)
(3, 9)
(4, 16)
(5, 25)
딕셔너리 정렬
딕셔너리 정렬을 위해서 sorted() 함수를 사용할 것 입니다. 다만 sorted() 함수는 언제나 list 타입을 반환하기 때문에 주의해야 합니다.
먼저 오름차순 정렬 입니다. 정렬 확인을 위해 아래와 같은 딕셔너리를 만들어 주고 lambda를 이용합니다.
hashd = {1:10, 3:12, 5:7, 7:6, 4:5}
print(hashd)
print(sorted(hashd.keys(), key = lambda x : x))
{1: 10, 3: 12, 5: 7, 7: 6, 4: 5}
[1, 3, 4, 5, 7]
hashd = {1:10, 3:12, 5:7, 7:6, 4:5}
print(hashd)
print(sorted(hashd.values(), key = lambda x : x))
{1: 10, 3: 12, 5: 7, 7: 6, 4: 5}
[5, 6, 7, 10, 12]
hashd = {1:10, 3:12, 5:7, 7:6, 4:5}
print(hashd)
print(sorted(hashd.items(), key = lambda x : x))
{1: 10, 3: 12, 5: 7, 7: 6, 4: 5}
[(1, 10), (3, 12), (4, 5), (5, 7), (7, 6)]
다음은 내림차순 정렬입니다. lambda x : -x를 주어 정렬 가능합니다.
hashd = {1:10, 3:12, 5:7, 7:6, 4:5}
print(hashd)
print(sorted(hashd.keys(), key = lambda x : -x))
{1: 10, 3: 12, 5: 7, 7: 6, 4: 5}
[7, 5, 4, 3, 1]
hashd = {1:10, 3:12, 5:7, 7:6, 4:5}
print(hashd)
print(sorted(hashd.values(), key = lambda x : -x))
{1: 10, 3: 12, 5: 7, 7: 6, 4: 5}
[12, 10, 7, 6, 5]
items를 이용할경우 오름차순과 다르게 오류가 나는 것을 확인 할 수 있습니다.
hashd = {1:10, 3:12, 5:7, 7:6, 4:5}
print(hashd)
print(sorted(hashd.items(), key = lambda x : -x))
{1: 10, 3: 12, 5: 7, 7: 6, 4: 5}
---------------------------------------------------------------------------
TypeError Traceback (most recent call last)
<ipython-input-75-e1d40831b786> in <module>
1 hashd = {1:10, 3:12, 5:7, 7:6, 4:5}
2 print(hashd)
----> 3 print(sorted(hashd.items(), key = lambda x : -x))
<ipython-input-75-e1d40831b786> in <lambda>(x)
1 hashd = {1:10, 3:12, 5:7, 7:6, 4:5}
2 print(hashd)
----> 3 print(sorted(hashd.items(), key = lambda x : -x))
TypeError: bad operand type for unary -: 'tuple'
이유는 lambda x : x 에 들어가는 값이 튜플 이기 때문입니다. 튜플은 -(a, b) 와 같은 형태로 줄 수가 없기 때문입니다.
그래서 items를 사용시에는 어떤 값을 기준으로 정렬할지를 명시해 줘야 합니다.
hashd = {1:10, 3:12, 5:7, 7:6, 4:5}
print(hashd)
print(sorted(hashd.items(), key = lambda x : x[0]))
print(sorted(hashd.items(), key = lambda x : x[1]))
{1: 10, 3: 12, 5: 7, 7: 6, 4: 5}
[(1, 10), (3, 12), (4, 5), (5, 7), (7, 6)]
[(4, 5), (7, 6), (5, 7), (1, 10), (3, 12)]